Spetlr
A python ETL libRary (SPETLR) for Databricks powered by Apache SPark.
Enables a standardized ETL framework and integration testing for Databricks.
Project maintained by spetlr-org Hosted on GitHub Pages — Theme by mattgraham
![]()
Why use SPETLR?
See SPETLR Documentation.
From a developer’s perspective:
-
ETL framework: A common ETL framework that enables reusable transformations in an object-oriented manner. Standardized structures facilitate cooperation in large teams.
-
Integration testing: A framework for creating test databases and tables before deploying to production in order to ensure reliable and stable data platforms. An additional layer of data abstraction allows full integration testing.
-
Handlers: Standard connectors with commonly used options reduce boilerplate.
From a business perspective:
-
Maintained code: Using SPETLR in your data platform, your ETL code base is maintained by the contributors to SPETLR.
-
Development time saving: Reuse ETL processes across different projects.
-
No secrets: SPETLR is open-source.
SPETLR has a lot of great tools for working with ETL in Databricks. But to make it easy for you to consider why you need SPETLR here is a list of the core features:
- Core feature: (O) ETL Framework
- Core feature: Integration test for Databricks
- Core feature: Data source handlers
Core feature: (O) ETL Framework
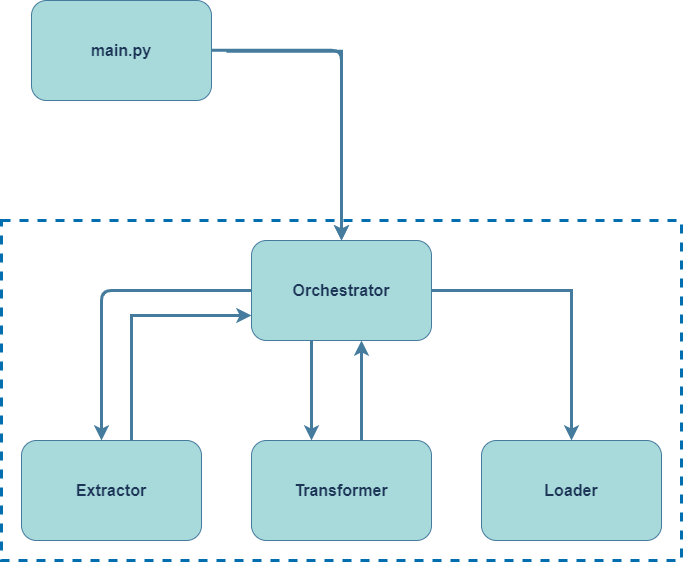
Short for Orchestrated Extract-Transform-Load is a pattern that takes the ideas behind variations of the Model-View-Whatever design pattern.
A very short overview of the framework:
- Extractor: Reads data
- Transformer: Transform data
- Loader: Saves data
from spetlr.etl import Extractor, Transformer, Loader, Orchestrator
(Orchestrator()
.extract_from(Extractor())
.transform_with(Transformer())
.load_into(Loader())
.execute())
Behind the scenes
How do the framework handle the dataframes?
The framework handles the dataframes in a Dataset dictionary: {key: DataFrame}.
- Dataframes are stored in a dict that flows through the ETL stages
- Extractor: Adds DataFrame to the dict
- Transformer Manipulates DataFrame(s) in dict
- Loader: Save DataFrame from dict to a location (e.g. Delta table)
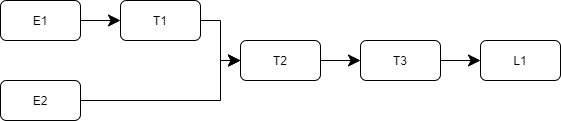
Example: In the code and figure below, you can see an example of how data can flow through the SPETLR ETL framework:
from spetlr.etl import Extractor, Transformer, Loader, Orchestrator
(Orchestrator()
.extract_from(ExtractorE1(dataset_key="E1"))
.extract_from(ExtractorE2(dataset_key="E2"))
.transform_with(TransformerT1())
.transform_with(TransformerT2())
.transform_with(TransformerT3())
.load_into(LoaderL1())
.execute())
Why should you use the SPETLR OETL framework?
- Modular ETL concept for building complex flows
- Reusability of modules: Instead of writing the same pyspark code again and again, build it as an SPETLR ETL module that can be reused across multiple ETL workflows.
- Unit testing: Each extractor, transformer, and loader can be unit-tested individually.
- Integration testing: The modular design makes it possible to perform integration tests on various combinations of the ETL modules. Use the SPETLR table abstraction to enable debug tables for testing - see previous section.
Core feature: Integration test for Databricks
SPETLR provides a framework for creating test databases and tables before deploying to production. This is a must-have for Lakehouse platform in order to ensure reliable and stable data platforms.
Concept: Table abstractions
Every table exists in two “places”:
- As data – with schema and contents (e.g. a delta table in a storage account)
- As a concept in code (e.g. as Spark SQL code)
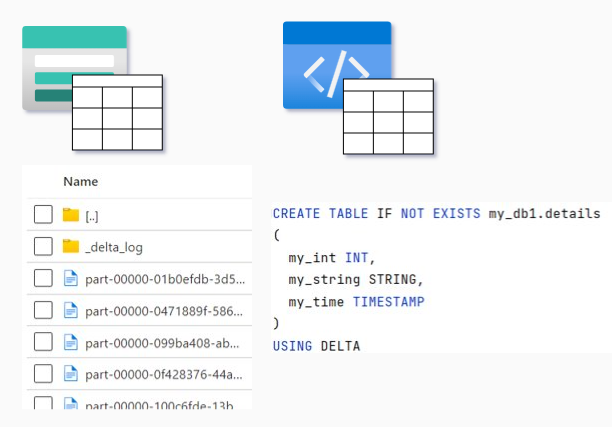
The left part (the delta schema in a storage account) is the actual state and the right part (Spark SQL code) is the desired state.
Let us say, that the ETL process is changed in a new Pull Request. How do we ensure that the new code actually works? How do we ensure that the ETL processes works on the new desired state?
The SPETLR solution is debug tables. The process works as follows:
- Ensure code works on a debug table
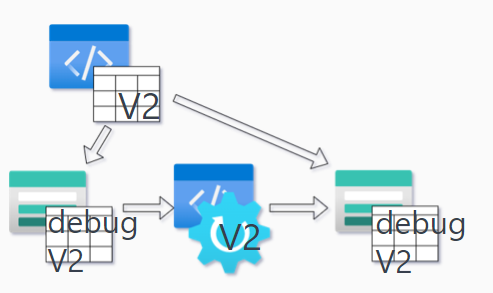
- Deploy to production
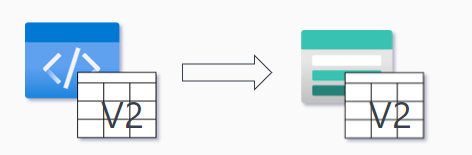
- Deploy ETL
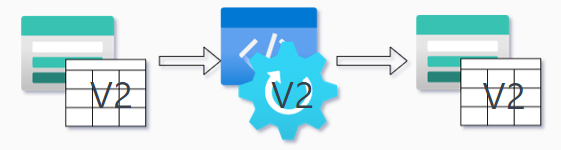
Pull Request problem and the SPETLR solution
The next question is then: How to create debug tables?
It is done by introducing dynamic table names. A delta table is not refferenced by the actual state name, but instead the code refers to a configurator key:
-- spetlr.Configurator key: MyDetailsTable
CREATE TABLE IF NOT EXISTS `my_db1{ID}.details`
(
a int,
b int,
c string,
d timestamp
)
USING DELTA
COMMENT "Dummy Database 1 details"
LOCATION "/{MNT}/foo/bar/my_db1{ID}/details/";
The “MyDetailsTable” is used for reference in the SPETLR handler classes (DeltaHandle, SqlHandle, etc.).
When debugging the following variables are set to:
- {ID} = a GUID
- {MNT} = tmp
When code is used in production the variables are set:
- {ID} = “”
- {MNT} = mnt
(NB: The MNT is used for Databricks workspaces that uses mounting to access storageaccounts. When using direct access, a similar variable as MNT can change the path to the storage account.)
Tool support
Keys needs to be configured:
from spetlr import Configurator
Configurator().add_resource_path("path/to/sql_files")
All tables’ access needs to use abstractions:
# Dont use
df = spark.table("my_db.details1")
# but use SPETLR
from spetlr.delta import DeltaHandle
df = DeltaHandle.from_tc("MyDetailsTable").read()
The Configurator is a singleton, and the .from_tc() method accesses the singleton. SQL code gets treated before execution (variables replaced).
Test execution (debug tables)
To execute a test:
# Set the configurator in debug mode
# ID = a GUID
# MNT = "tmp"
Configurator().set_debug()
# SqlExecutor utilizes the Configurator to parse SQL files
SqlExecutor("path/to/sql_files").execute_sql_file("*")
MyEtlOrchestrator().execute()
Production ETL
To execute production:
# Set the configurator in debug mode
# ID = ""
# MNT = "mnt"
Configurator().set_prod()
# SqlExecutor utilizes the Configurator to parse SQL files
SqlExecutor("path/to/sql_files").execute_sql_file("*")
MyEtlOrchestrator().execute()
Test improvements
SPETLR team recommends:
- Write test data to debug tables
- Assert on contents from target tables
- Can be done by injecting SPETLR-tools’s TestHandle
Summary
SPETLR contributes with the following:
- Added abstraction on tables
- Allows full testing of table creation and ETL code
- Good tool support gives minimal added complexity
Core feature: Data source handlers
SPETLR provide classes for handle reads and writes to different data sources from primarily Azure resources.
The object-oriented structure makes it easy to change handlers in the ETL flows that can handle different data sources with minimal code duplication.
The handlers are well-tested against real Azure resources to ensure high quality and reliability. They can be used out of the box in various projects without needing extensive customization.
The handlers use primarly PySpark under the hood. Therefore, the handlers are a convenient way to streamline the process of working with multiple data sources in ETL flows.
In the code
from spetlr.cosmos import CosmosHandle
from spetlr.delta import DeltaHandle
from spetlr.etl import Extractor, Transformer, Loader, Orchestrator
from spetlr.sql import SqlHandle
# Eventhub not yet implemented as Handle
from spetlr.eh import EventHubCaptureExtractor
dh = DeltaHandle.from_tc("DeltaTableId")
eh = EventHubCaptureExtractor.from_tc("EventhubCaptureTableId")
sqlh = SqlHandle.from_tc("SQLTableId")
cosmosh = CosmosHandle.from_tc("CosmosTableId")
# All handles have the same methods
# The SimpleLoader uses the handlers' .read() method.
# You can use the SimpleLoader regardless
# of which kind of data source you use
(Orchestrator().
.extract_from(SimpleLoader(handle=dh))
.extract_from(SimpleLoader(handle=eh))
.extract_from(SimpleLoader(handle=sqlh))
.extract_from(SimpleLoader(handle=cosmosh))
...
)
Why should you use the data source handlers?
- Remove repetitive code: SPETLR provides easy-to-read methods for simplifying repetitive code. For example,
pyspark.read.mode("append").load()->.append() - Simplicity: Handlers inherit the same methods from a common base class, which makes them easy to use and understand.
- Well tested: The handlers undergo testing within SPETLR to ensure reliability and quality.